
GoogleドキュメントのOCR機能に34の言語が追加されました。お待ちかねの日本語も。
» Optical Character Recognition (OCR) in 34 languages – Docs Blog
ということで、このブログのトップページををPDFで落として、どの程度の精度で文字を認識できるのか試してみました。ファイルはこちらからアップロードします。アップロードの際、「PDF や画像ファイルからテキストを Google ドキュメントのドキュメントに変換する」にチェックマークを入れること。
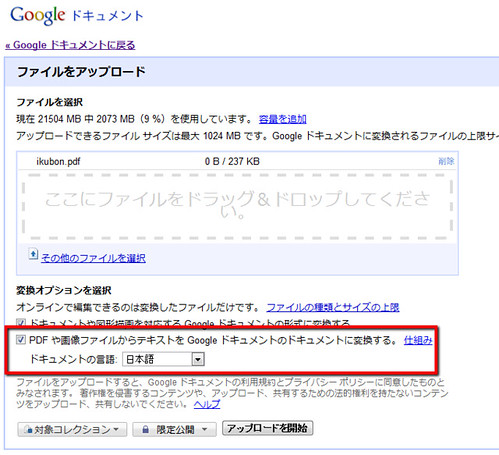
今回アップロードさせた文書は4ページほどの量でしたが、ほとんど待ち時間なくでドキュメントに変換しました。できあがりはこのように、画像の後に変換した文書が続きます。
次にどの程度の精度で文字を認識しているのか、みてみることに。この部分がどのように読み込まれたかというと…

こんな感じで、完璧にテキストに落としてくれています。

無料で、この精度、最強です。いろいろな使い方ができるのでは。Evernoteの代わりになっちゃうかも。